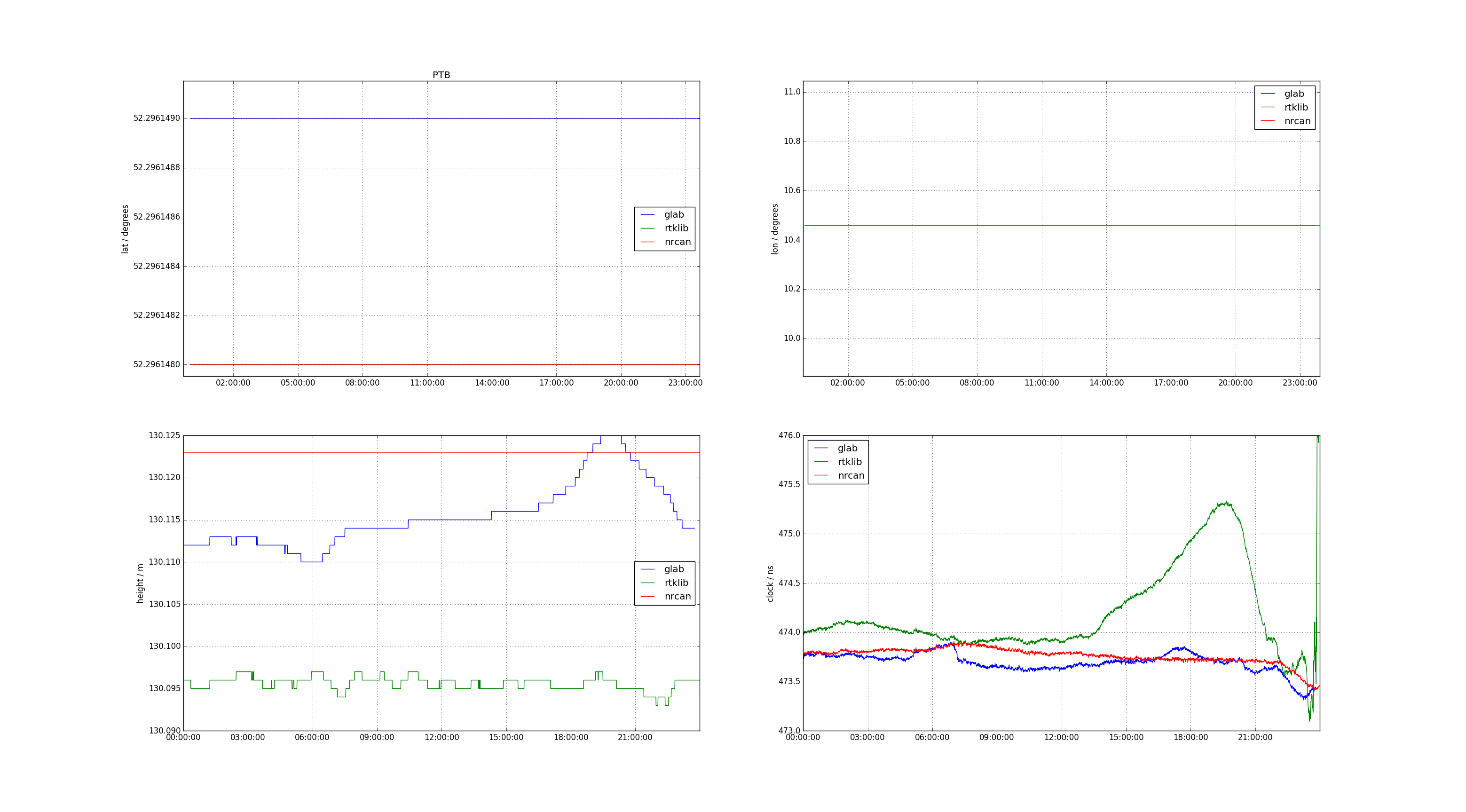
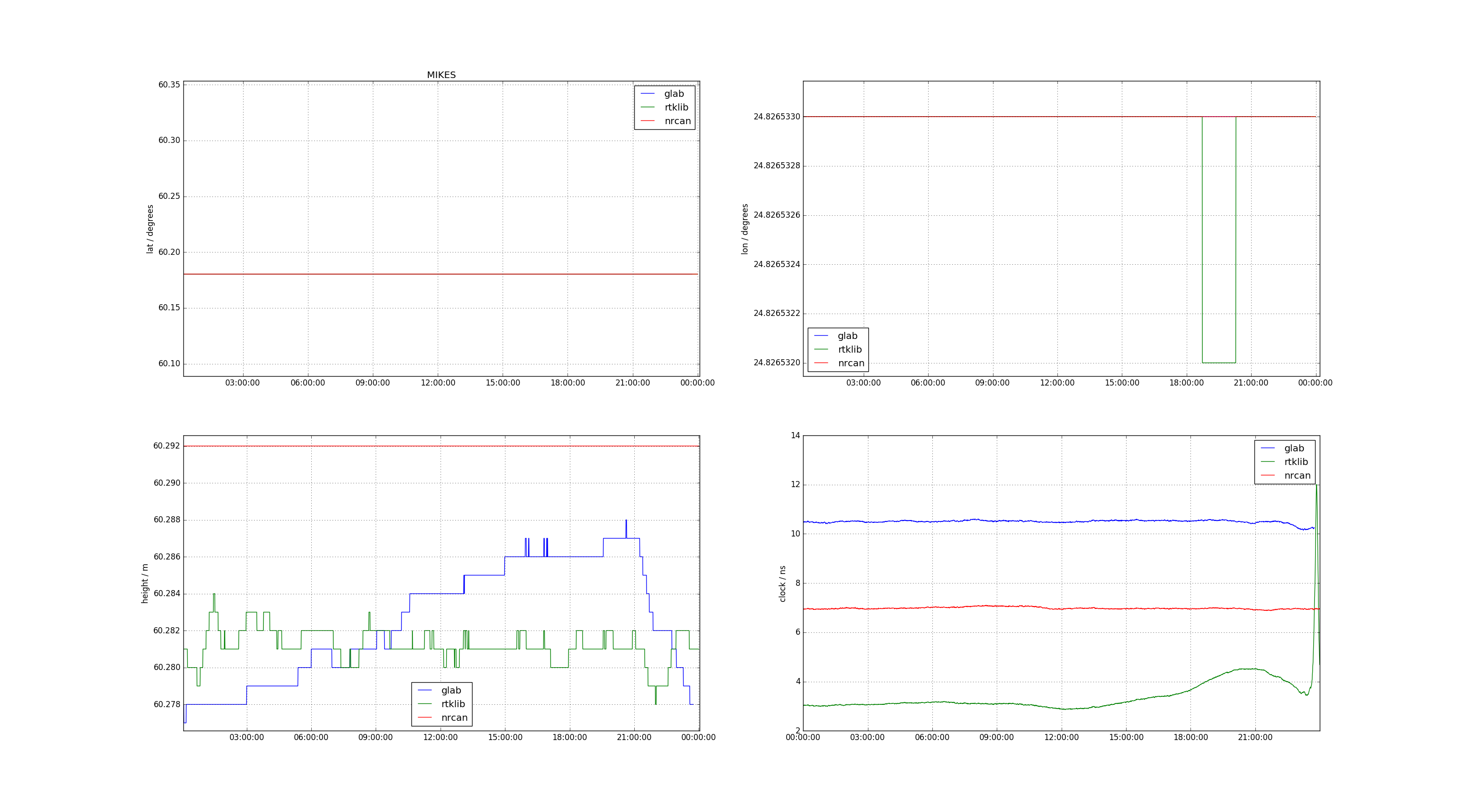
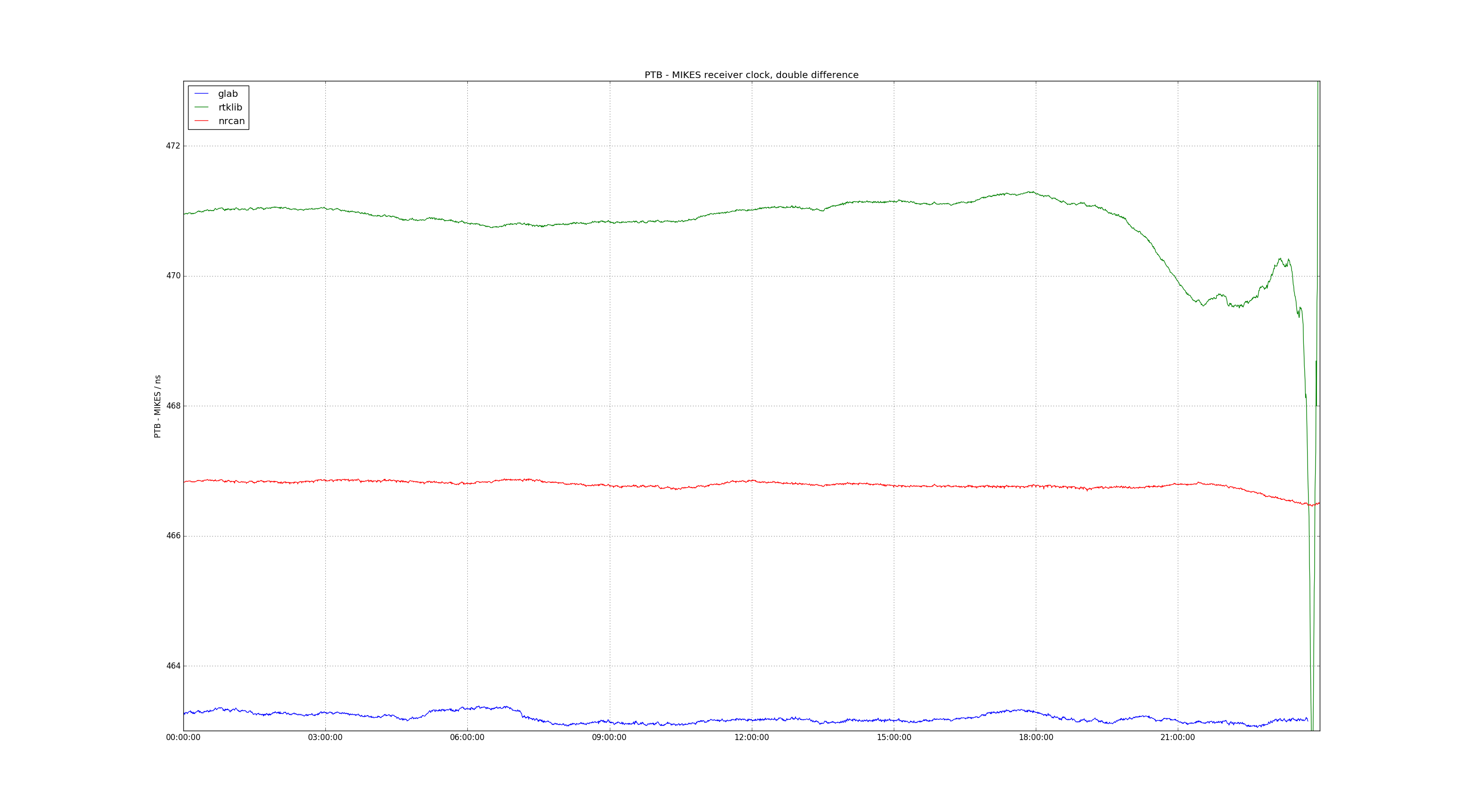
Here's an example of using PPP-tools to compare PPP solutions from NRCan gpsppp, ESA gLAB, and RTKLIB.
PTBG receiver.
MI04 receiver
Receiver clock double difference, PTBG – MI04
It seems that all programs fix the lat/lon output. However both gLAB and RTKLIB leave the height as a variable parameter. Interestingly it seems there is some peak at the end of the PTBG data and gLAB compensates by raising the height while RTKLIB compensates by raising the clock value.
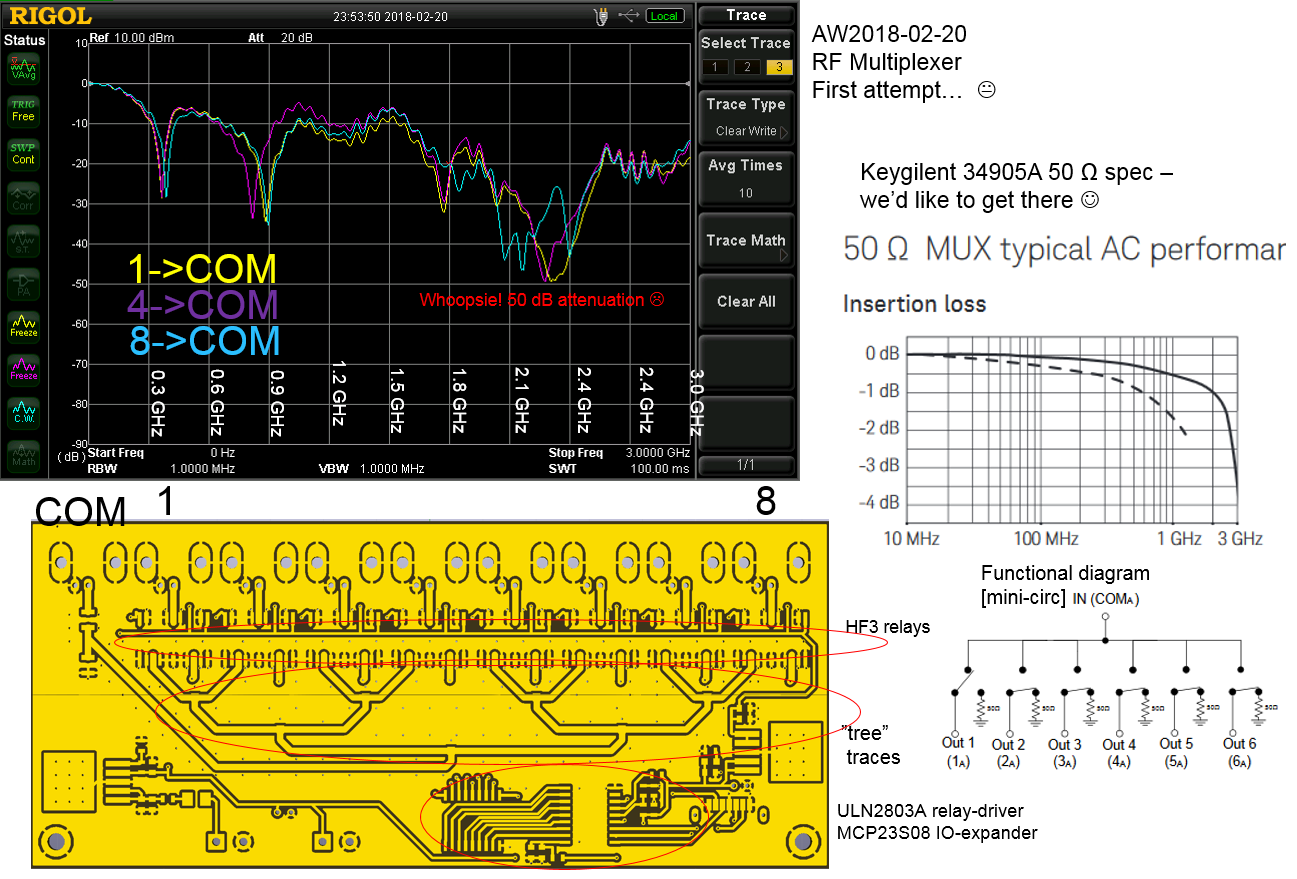
RF Multiplexer, 8 inputs, 1 output, BNC-connectors, TE HF3 relays specified to 3 GHz, an ULN2803A to pull the relay-coil, and an SPI I/O expander to drive the ULN - should be easy - right?
Well no, PCB trace-geometry does strange things beyond VHF. I clearly don't grok UHF very well.
Onward towards version 2! (any thoughts and advice on simulation or trace-geometry optimizers appreciated!)
For isolated 1PPS distribution I made this distribution board.
The input is a TLP117 (or similar) optoisolator driving a LT1711 comparator with a 1.0 V trigger level. An output LED-blink is provided by LTC6993. Outputs are driven by IDT5PB1108 buffers.
In jitter measurements with a HPAK 53230A counter the jitter between two 1PPS pulses (from masers) seems to degrade slightly through this amplifier: from RMS 16-19 ps directly on the maser-outputs to between 21 and 26 ps RMS from the outputs of the ISOPDA. Maybe a faster optoisolator would be better?
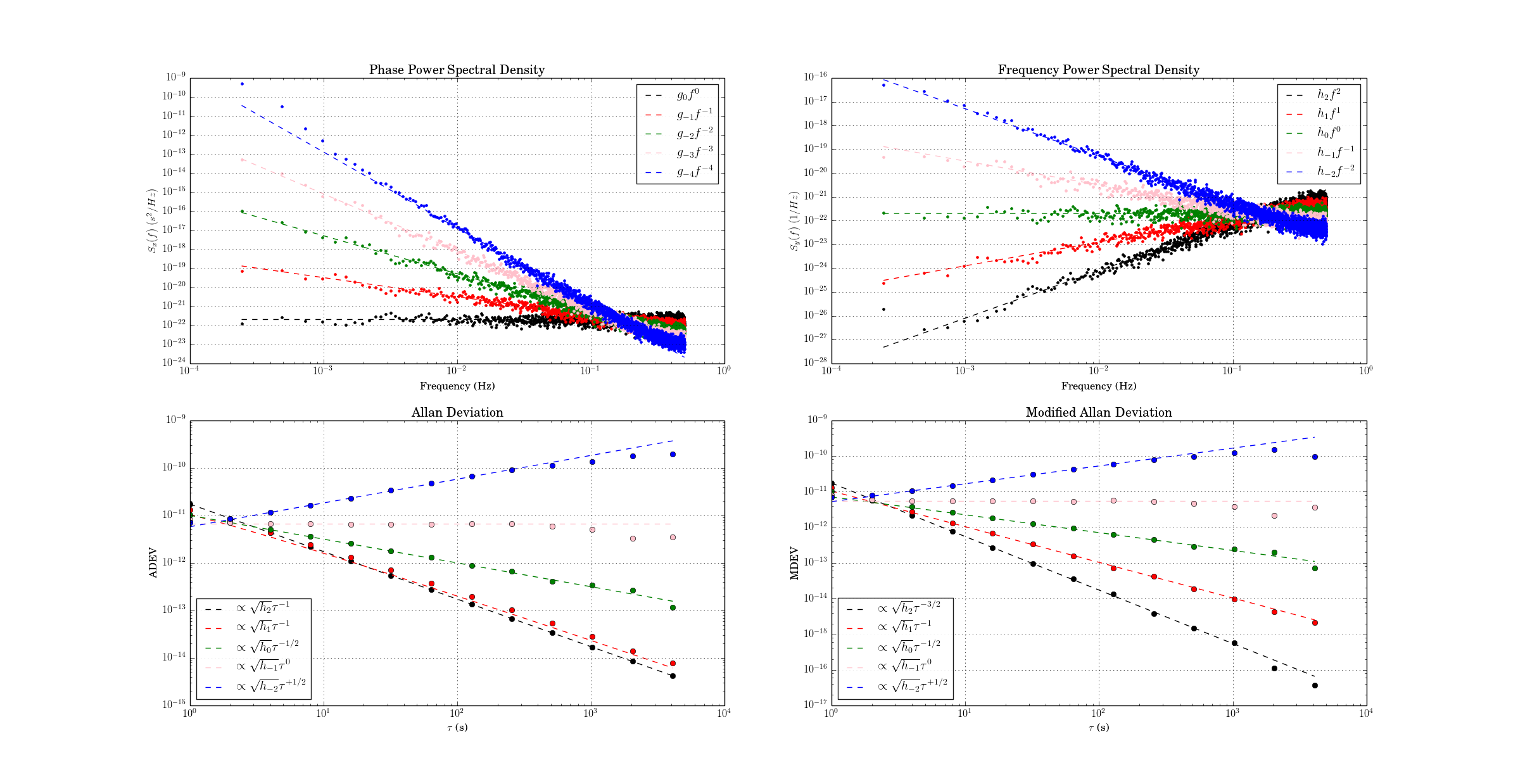
The usual noise-types studied have phase PSD noise-slopes "b" ranging from 0 to -4 (or even -5 or -6), corresponding to frequency PSD noise-slopes "a" ranging from +2 to -2 (where a=b+2). These 'colors of noise' can be visualized like this:
Four colors of noise. Note frequency PSD slope "a" related to phase PSD slobe "b" by a=b+2. Lower graphs show tau-slopes "mu" for ADEV and MDEV. Data point colors don't match with figures below - sorry.
I've implemented three noise-identification algorithms based on Stable32-documentation and other papers: B1, R(n), and Lag-1 autocorrelation.
B1 (Howe 2000,Barnes1969) is defined as the ratio of the standard N-sample variance to the (2-sample) Allan variance. From the definitions one can derive an expected B1 ratio of (the length of the time-series is N)
where mu is the tau-exponent of Allan variance for the noise-slope defined by b (or a). Since mu is the same (-2) for both b=0 and b=-1 (red and green data) we can't use B1 to resolve between these noise-types. B1 looks like a good noise-identifier for b=[-2, -3, -4] where it resolves very well between the noise types at short tau, and slightly worse at longer tau.
R(n) can be used to resolve between b=0 and b=-1. It is defined as the ratio MVAR/AVAR, and resolves between noise types because MVAR and AVAR have different tau-slopes mu. For b=0 we expect mu(AVAR, b=0) = -2 while mu(MVAR, b=0)=-3 so we get mu(R(n), b=0)=-1 (red data points/line). For b=-1 (green) the usual tables predict the same mu for MVAR and AVAR, but there's a weak log(tau) dependence in the prefactor (see e.g. Dawkins2007, or IEEE1139). For the other noise-types b=[-2,-3,-4] we can't use R(n) because the predicted ratio is one for all these noise types. In contrast to B1 the noise identification using R(n) works best at large tau (and not at all at tau=tau0 or AF=1).
The lag-1 autocorrelation method (Riley, Riley & Greenhall 2004) is the newest, and uses the predicted lag-1 autocorrelation for (WPM b=0, FPM b=-1, WFM b=-2) to identify noise. For other noise types we differentiate the time-series, which adds +2 to the noise slope, until we recognize the noise type.
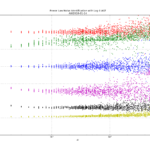
Here are three figures for ACF, B1, and R(n) noise identification where a simulated time series with known power law noise is first generated using the Kasdin&Walter algorithm, and then we try to identify the noise slope.
Lag-1 ACF noise-identification. Resolves well between all noise types at short and medium tau.
B1 noise-identification. Resolves well between b=-2…-4 at short and medium tau.
R(n) noise identification. Resolves well between b=0, -1 at medium and long tau. Note weak log(tau) dependence for b=-1 (green)
For Lag-1 ACF when we decimate the phase time-series for AF>1 there seems to be a bias to the predicted a (alpha) for b=-1, b=-3, b=-4 which I haven't seen described in the papers or understand that well. Perhaps an aliasing effect(??).
It turns out there's quirky convention of writing out the 40-character SHA1 checksum in 5 groups of 8 hex characters - whith the special undocumented rule that leading zeros are suppressed. This means the SHA1 check fails for some files where we happen to have a leading zero in one of the 8-character groups - unless you happen to know about the undocumented rule...
The output looks like this. "New" is the checksum computed by the program, "Old" is the checksum contained in the published file.
There's also another simple script for authoring a leap-seconds.list file. It might be used for adding an artificial leap-second, generating a leap-seocnds.list file, and testing how different devices react to a leap-second - without having to wait for a real leap-second event.
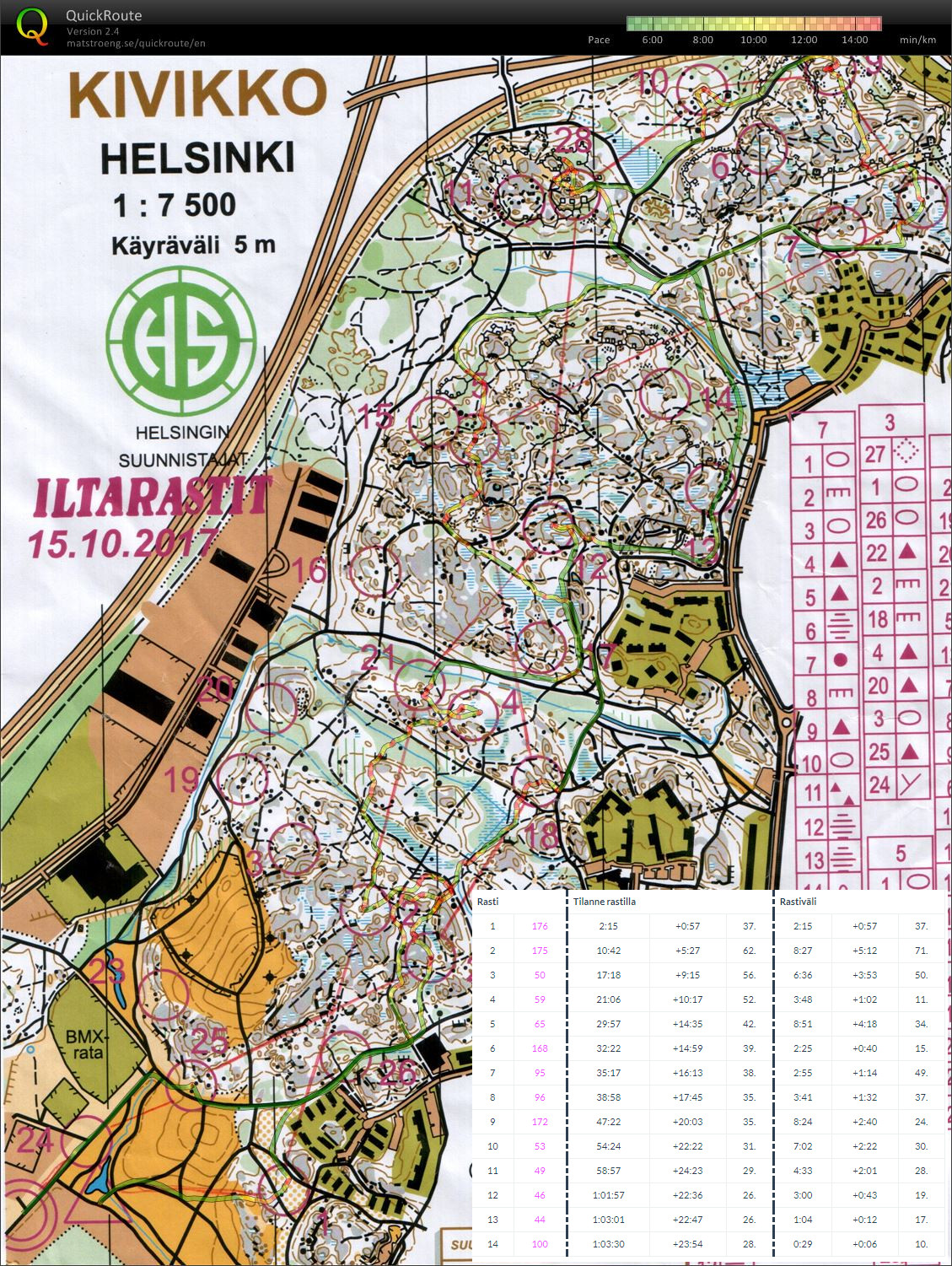
Missing the control circle on #2 from the large stones about 75m away, +5 min. Then too large a detour to #5 and about +4 min there. Otherwise mostly OK. Maybe +12 C and glimpses of sun.