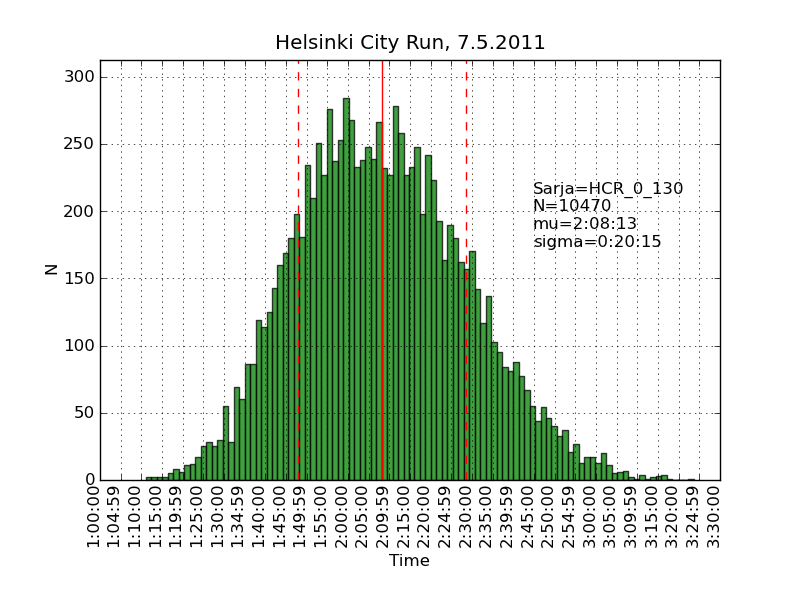
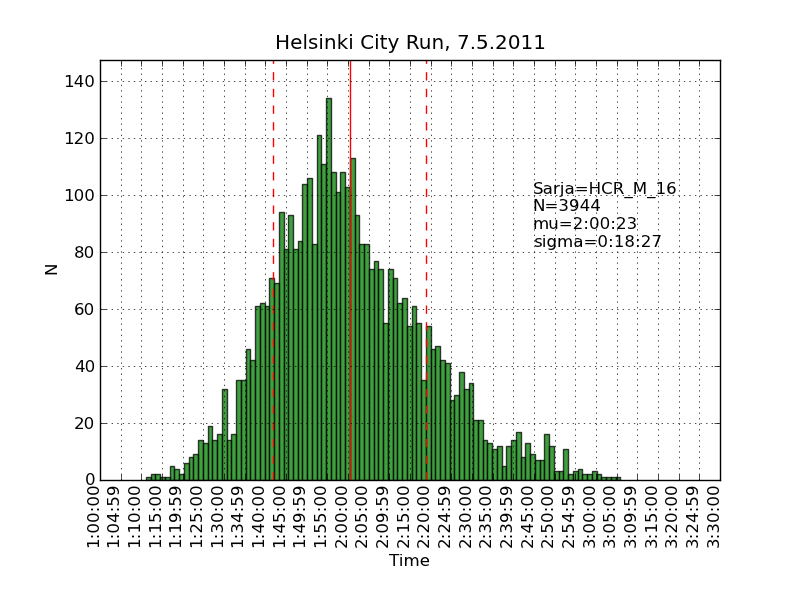
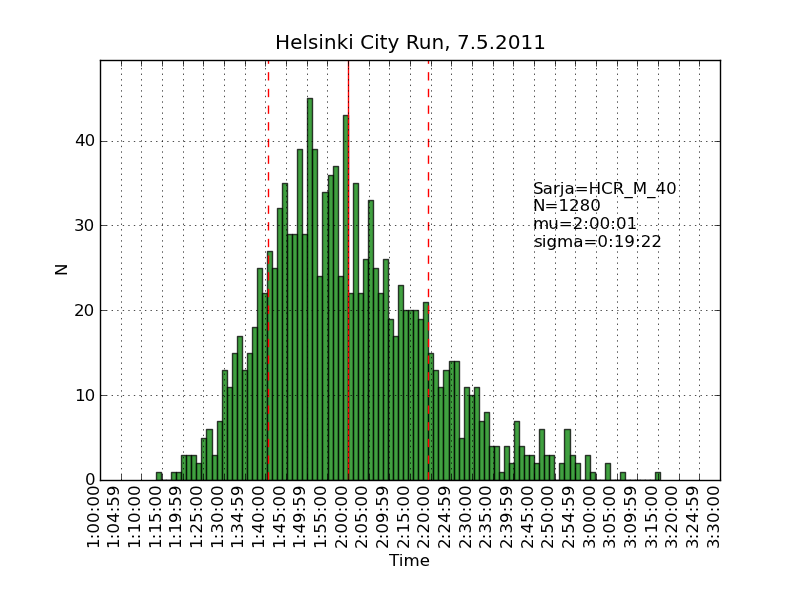
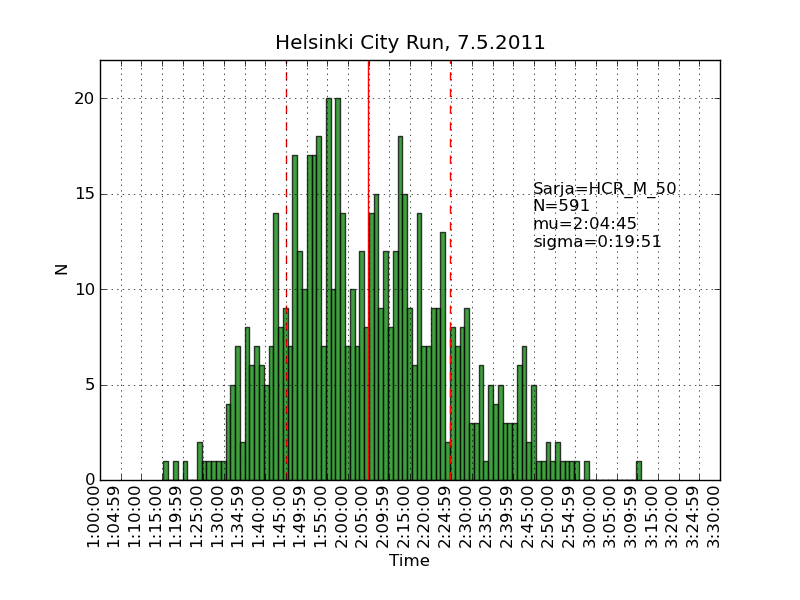
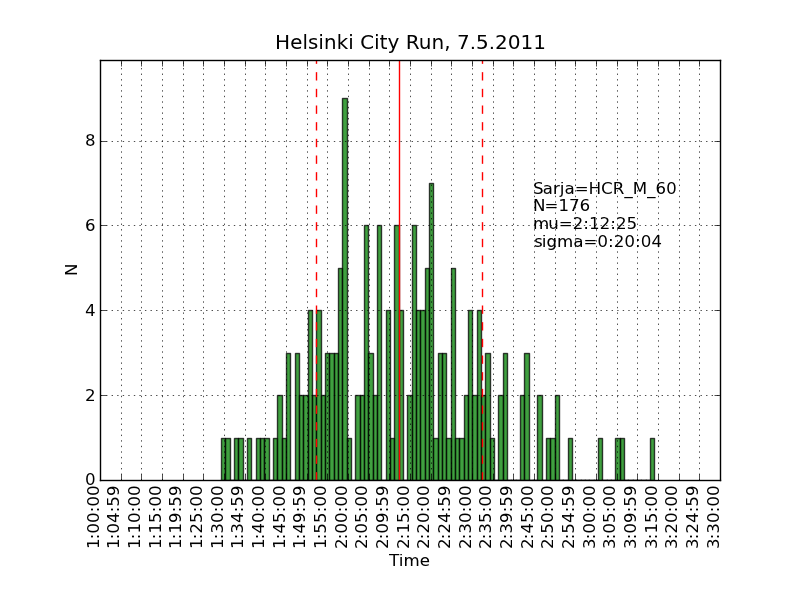
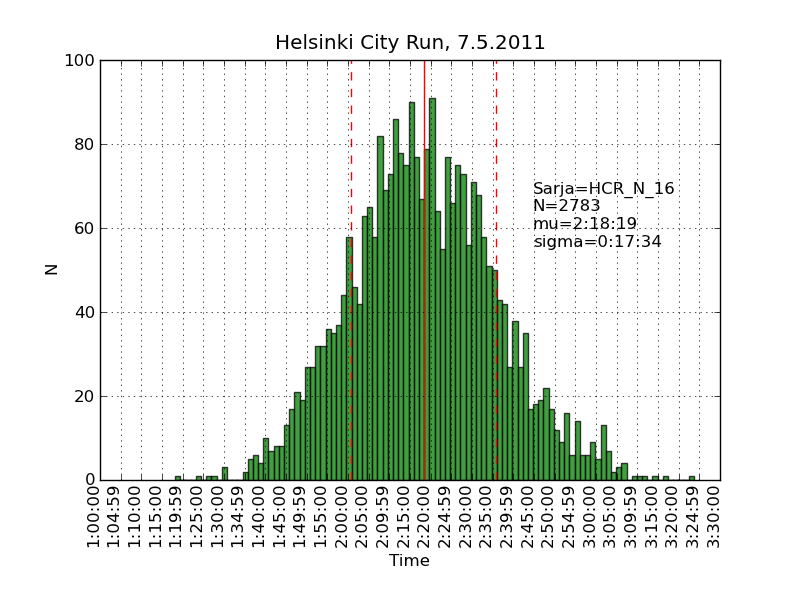
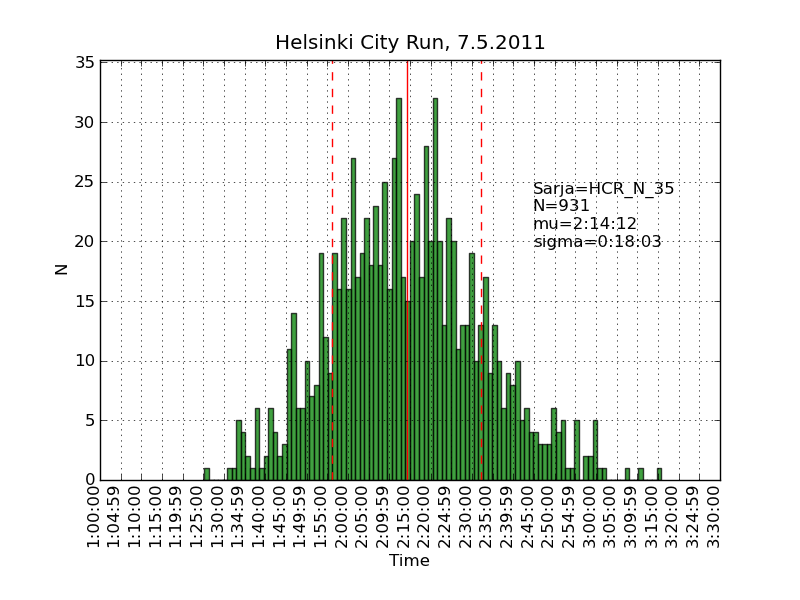
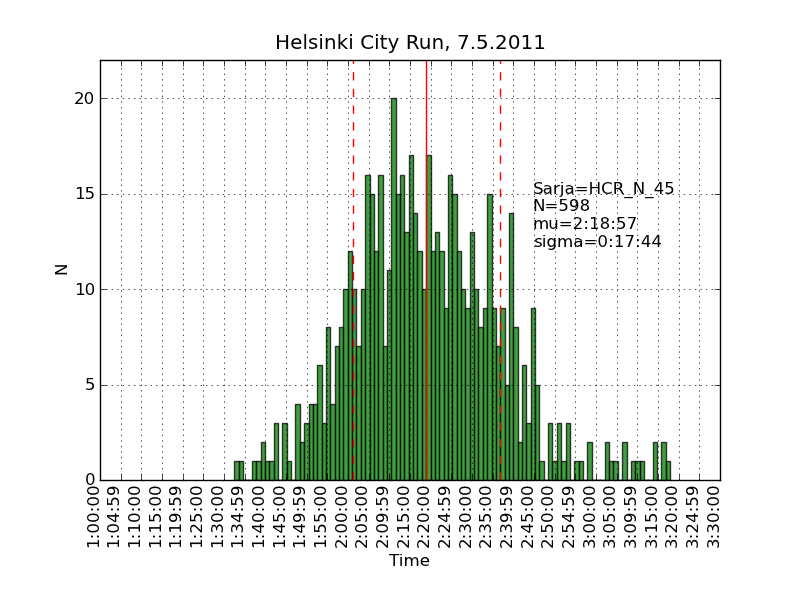
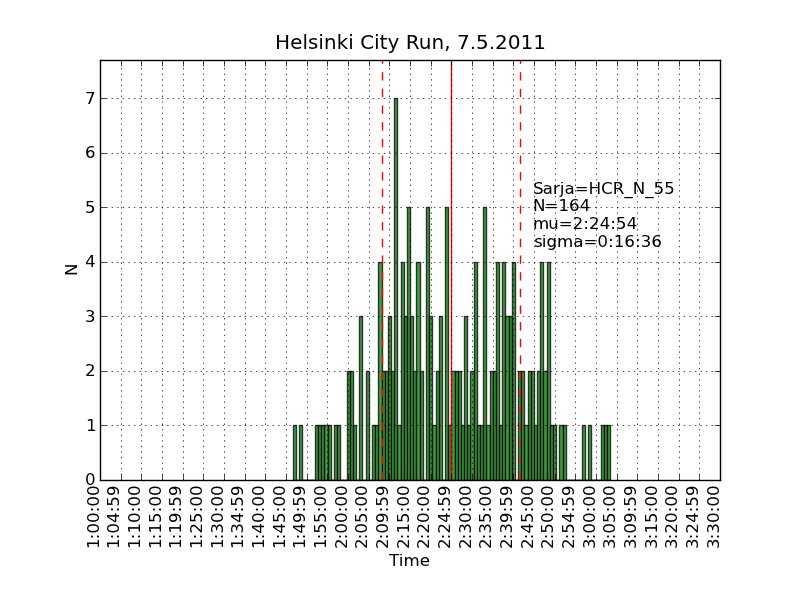
Using the same scraping scripts I wrote after last years marathon, it was fairly easy to scrape the HCR website and produce some histograms.
There are two python scripts, one that crawls the web (urllib) and finds the time-data (BeautifulSoup and re) and writes to a file (cPickle), and another that reads the files and plots (matplotlib) histograms: hcr2011_scrape